
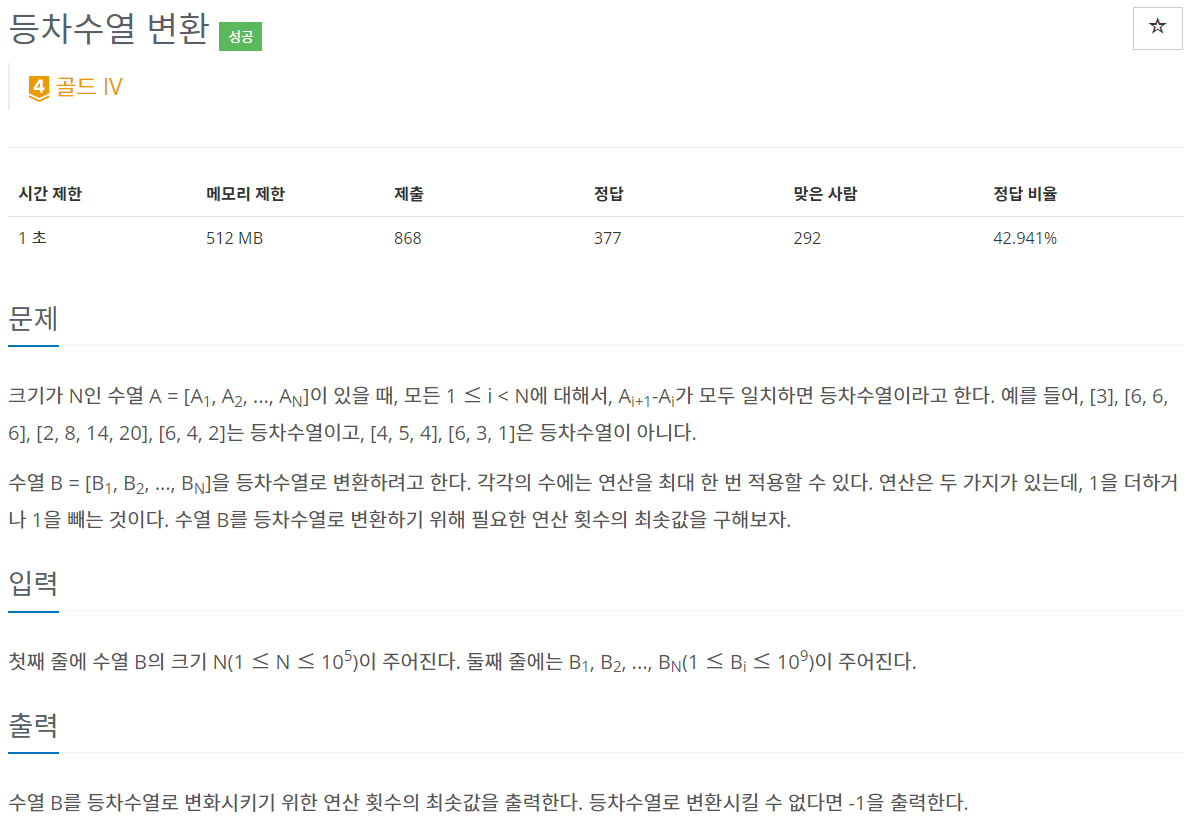
문제
문제 링크 : https://www.acmicpc.net/problem/17088
17088번: 등차수열 변환
크기가 N인 수열 A = [A1, A2, ..., AN]이 있을 때, 모든 1 ≤ i < N에 대해서, Ai+1-Ai가 모두 일치하면 등차수열이라고 한다. 예를 들어, [3], [6, 6, 6], [2, 8, 14, 20], [6, 4, 2]는 등차수열이고, [4, 5, 4], [6, 3, 1]
www.acmicpc.net
CODE
def check(i, j):
cnt = abs(i) + abs(j) # 연산 횟수; 1, 2번째 원소의 연산 횟수로 초기화
arr = []
arr.append(b[1] + j)
diff = b[1] + j - b[0] - i # 공차 == 1, 2번재 원소의 차
for k in range(2, n):
if b[k] == arr[k - 2] + diff:
arr.append(b[k])
elif b[k] - 1 == arr[k - 2] + diff:
arr.append(b[k] - 1)
cnt += 1
elif b[k] + 1 == arr[k - 2] + diff:
arr.append(b[k] + 1)
cnt += 1
else: # 배열의 원소 중 하나라도 조건에 해당되지 않으면,
return False # 배열은 등차 수열이 아님
return cnt
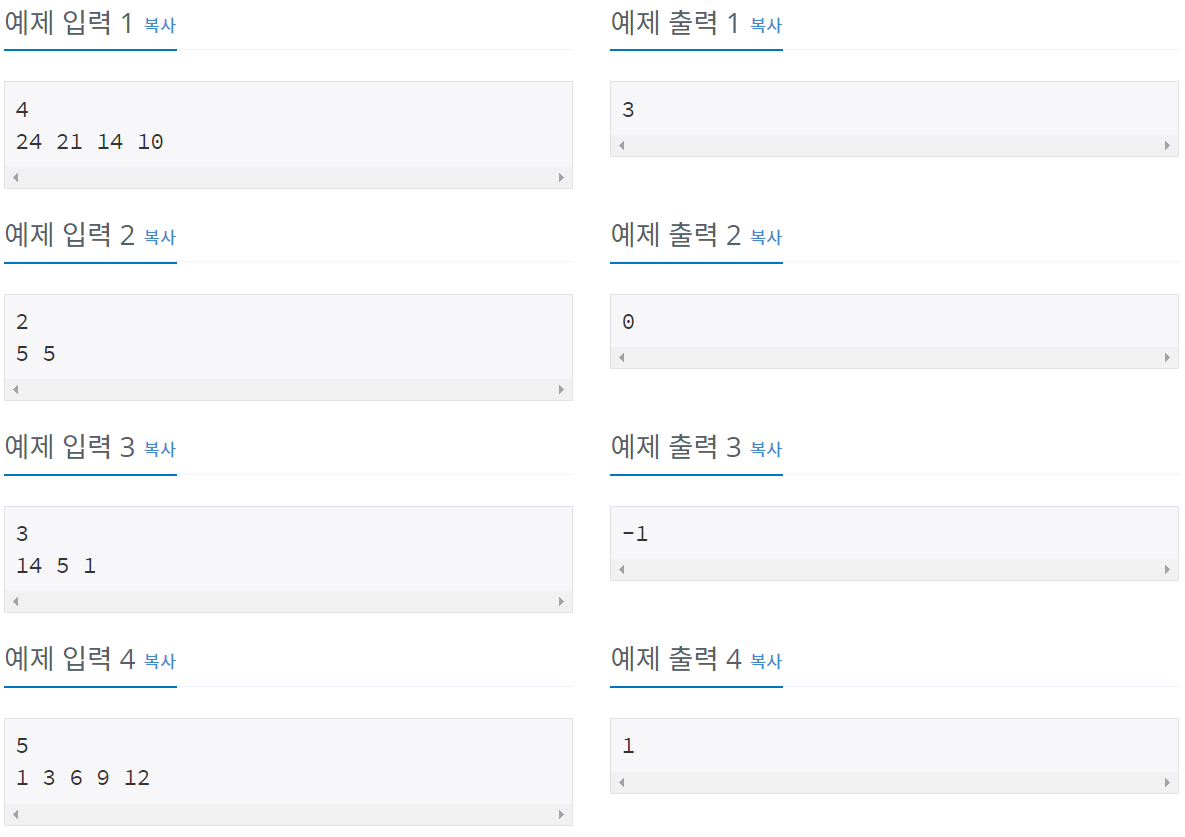
n = int(input())
b = list(map(int, input().split()))
result = 100001 # 수열의 최대크기 + 1
if n < 3: # n이 0,1,2인 경우
print(0) # 무조건 등차수열이기 때문에 연산 필요하지 않음
exit()
for i in range(-1, 2): # 첫 번째 원소에 연산을 적용할 값
for j in range(-1, 2): # 두 번재 원소에 연산을 적용할 값
temp = check(i, j)
if temp == False: # 등차 수열이 만들어 지지 않음
continue
else:
result = min(result, temp)
if result == 100001: # 등차 수열로 변환이 불가한 경우
print(-1)
else:
print(result)
풀이
💡 Idea
- ❌ 모든 원소에 -1,0,+1 연산한 경우를 계산 → 당연하게도 시간 초과 👽
- 첫 번째, 두 번째 원소에 대해서만 -1, 0, 1 연산 모두를 고려하여 등차 수열의 common difference(공차)를 구한다
: 항상 9가지 경우
- 공차를 구하고, 수열의 나머지 부분도 이 공차를 가지는 등차 수열이 될 수 있는지 검사하는 함수 check(i, j)
: 나머지 원소들에도 연산하는 경우를 고려한다
- 수열의 3~n 번째 원소를 순차적으로 검사하면서, 한번이라도 등차 수열이 성립되지 않으면 검사가 종료되기 때문에 전체 경우를 검사하는 것에 비해 시간이 단축된다!
💡 Implementation
처음엔 다음과 같이 check함수에 원본 리스트 b를 복사한 bb를 인수로 넘겨서 연산을 할 때마다 bb 원소를 직접 변경하여 사용하였다
import copy
def check(i, j, arr):
cnt = abs(i) + abs(j)
arr[0], arr[1] = arr[0] + i, arr[1] + j
diff = arr[1] - arr[0]
# print("b:", arr, "diff:",diff)
for k in range(2, n):
if arr[k] == arr[k - 1] + diff:
continue
elif arr[k] - 1 == arr[k - 1] + diff:
arr[k] -= 1
cnt += 1
elif arr[k] + 1 == arr[k - 1] + diff:
arr[k] += 1
cnt += 1
else:
return False
return cnt
n = int(input())
b = list(map(int, input().split()))
result = 100001
if n < 3:
print(0)
exit()
for i in range(-1, 2):
for j in range(-1, 2):
bb = copy.deepcopy(b)
temp = check(i, j, bb)
if temp == False:
continue
else:
result = min(result, temp)
if result == 100001:
print(-1)
else:
print(result)시간초과가 뜨지는 않았지만 파이썬으로 제출한 사람들 중에 시간이 꼴찌였다 😱 580ms ㅋㅋ
원본 리스트 전체를 복사를 하는 것 자체도 비효율적이지만, deepcopy() 함수의 느린 속도가 주된 원인이었다
깊은 복사를 할 때, deepcopy()보다는 slicing을 사용하는 것이 훨씬 빠르다.
위 코드에서 deepcopy() 로 원본 배열을 깊은 복사 하는 부분만 slicing으로 다음과 같이 바꾸었을 때,
# bb = copy.deepcopy(b)
bb = b[:]180ms로 시간이 단축되었다!
최종 코드를 작성할 때는 깊은 복사 자체를 없앴다
등차 수열 검사를 k번째 원소에서 중단하는 경우에 원본 배열의 (k+1) ~ n 번째 원소는 복사될 필요가 없다!
따라서 검사한 원소만 새로운 배열 arr에 append() 하여 다음 원소 검사에 사용하였다
결과

'Baekjoon' 카테고리의 다른 글
| [BOJ / 백준] 2210번 숫자판 점프 파이썬(Python) 문제 풀이 (0) | 2021.08.01 |
|---|---|
| [BOJ / 백준] 15686번 치킨 배달 파이썬(Python) 문제 풀이 (1) | 2021.08.01 |
| [BOJ / 백준] 3425번 고스택 파이썬(Python) 문제 풀이 (0) | 2021.07.26 |
| [BOJ / 백준] 16943번 숫자 재배치 파이썬(Python) 문제 풀이 (0) | 2021.07.26 |
| [BOJ / 백준] 16938번 캠프 준비 파이썬(Python) 문제 풀이 (0) | 2021.07.25 |