
728x90
0. 동기 / 비동기 & 블로킹 / 논블록킹
- 동기 / 비동기 : 요청한 작업에 대해 완료 여부를 신경 써서 작업을 순차적으로 수행할지 아닌지 관점
- 블로킹 / 논블록킹 : 현재 작업이 block(차단, 대기) 되느냐 아니냐에 따라 다른 작업을 수행할 수 있는지 관점
0.1. 동기(Synchronous) vs 비동기(Asynchronous)
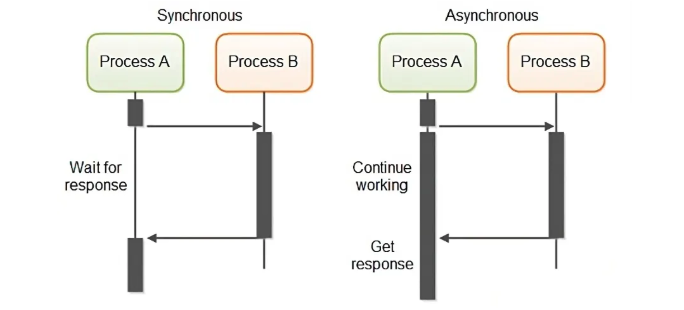
- 요청한 작업에 대해 완료 여부를 신경 써서 작업을 순차적으로 수행할지 아닌지
- 전체적인 작업에 대한 순차적인 흐름 유무

- 동기 : 요청한 작업에 대해 완료 여부를 따져 순차대로 처리하는 것
- 요청한 작업에 대해 순서가 지켜진다
- 비동기 : 요청한 작업에 대해 완료 여부를 따지지 않기 때문에 자신의 다음 작업을 그대로 수행
- 요청한 작업에 대해 순서가 지켜지지 않을 수 있다
- 느린 작업(like I/O 작업)이 발생할 때, 기다리지 않고 다른 작업을 처리하면서 멀티 작업 진행 가능
- 전반적인 시스템 성능 향상에 도움
- 동시 처리 → 멀티 스레드 / 멀티 프로세스 같은 방식으로 구현 가능
1.2. Blocking vs Non-Blocking

- 현재 작업이 block(차단, 대기) 되느냐 아니냐에 따라 다른 작업을 수행할 수 있는지
- 전체적인 작업의 흐름 자체를 막냐 안 막냐
- Example) 파일을 읽는 작업이 있을 때
- Blocking → 파일을 다 읽을 때까지 대기
- Non-Blocking → 파일을 다 읽지 않아도 다른 작업 가능

- 호출된 함수가 호출한 함수에게 제어권을 바로 주느냐 안주느냐로 Blocking / Non-Blocking 구분
- 제어권 : 함수의 코드나 프로세스의 실행 흐름을 제어할 수 있는 권리
- 운영체제의 커널(kernel)에서 I/O 동작을 설명하는 부분
- 제어권 : 함수의 코드나 프로세스의 실행 흐름을 제어할 수 있는 권리
1.3. 동기 / 비동기 + Blocking / Non-Blocking 조합

💡콜백(CallBack) 함수 : 비동기 / 논블로킹에서 다른 작업의 완료 여부나 결과에 대한 후처리를 위해 이용되는 방식
- Sync + Blocking
- 다른 작업이 진행되는 동안 자신의 작업을 처리하지 않고 (Blocking)
- 다른 작업의 완료여부를 받아 순차적으로 처리 (Sync)
- 다른 작업의 결과가 자신의 작업에 영향 주는 경우에 활용 가능
- Sync + Non-Blocking
- 다른 작업이 진행되는 동안에도 자신의 작업을 처리하고 (Non-Blocking)
- 다른 작업의 완료여부를 받아 순차적으로 처리 (Sync)
- 구현에 따라 Sync + Blocking 보다 효율적일 수 있음 (ex. 파일 다운로드 진행바)
- Async + Blocking
- 다른 작업이 진행되는 동안 자신의 작업을 처리하지 않고 (Blocking)
- 다른 작업의 결과를 바로 처리하지 않아 작업 순서가 지켜지지 않음 (Async)
- 실무에서 잘 다룰 일 없음
- Async + Non-Blocking
- 다른 작업이 진행되는 동안에도 자신의 작업을 처리하고 (Non-Blocking)
- 다른 작업의 결과를 바로 처리하지 않아 작업 순서가 지켜지지 않음 (Async)
- 다른 작업의 결과가 자신의 작업에 영향을 주지 않은 경우 활용 가능
1. 멀티 스레드
1.1. 스레드 (Thread)
💡 CPU 수행의 기본 단위 또는 프로세스 안의 제어권 프름
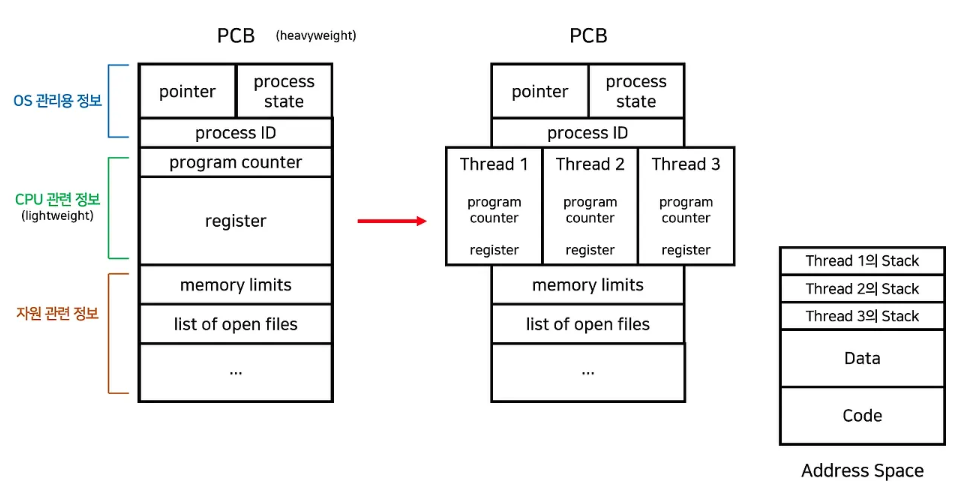
- 구성
- Thread ID
- Program Counter
- Register Set
- Stack Space
- 각각 스레드는 주로 최소한 자신의 레지스터 상태와 스택을 가진다
- Code / Data 섹션, 운영체제 자원들은 스레드끼리 공유
- 프로세스와의 비교
- 프로세스 생성 / Context Switching 작업은 무겁고 잦으면 성능 저하 발생
- 스레드를 생성하거나 Switching하는 것은 그에 비해 가벼움
- 프로세스간 데이터 공유를 위해서는 메시지 패싱 / 공유 메모리 또는 파이프 사용
- → 효율이 떨어지고 개발자가 구현, 관리하기 번거로움
- 프로세스 생성 / Context Switching 작업은 무겁고 잦으면 성능 저하 발생
- 유저 스레드(User-level Thread) : 커널 위에서 커널 지원 없이 유저 수준의 스레드 라이브러리(Thread Library)가 관리하는 스레드
- 안정성은 떨어지지만 성능 저하 X
- 커널 스레드(Kernel-level Thread) : 커널이 지원하는 스레드
- 안정적이지만 성능 저하 (유저 모드에서 커널모드로 바꿔줘야 하기 때문)
- 유저 스레드와 커널 스레드 사이 관계
- Many-to-One Model
- One-to-One Model
- Many-to-Many Model
- Two-level Model
1.2. 멀티 스레드 (Multi Thread)
💡 한 프로세스가 여러 스레드로 동시에 여러 작업을 수행하는 것
- 프로세서가 여러 개인 경우, 병렬성(Parallelism) 증가
- 프로세스의 스레드들이 각각 다른 프로세서에서 병렬적 수행 (병렬성은 CPU 개수에 비례)
- 프로세서가 하나인 경우, 동시성(Concurrency) 증가
- 실제로는 각각의 시간에 한 작업만 수행되지만, 병렬적으로 수행되는 것처럼 보인다
- 한 스레드가 Blocked 되더라도 커널이 다른 스레드로 Switch 시켜 실행 → 빠른 처리 계산 속도 증가
- 장점
- 응답성 (Responsiveness)
- 작업이 끝나기 전 사용자에게 응답하지 않는 싱글 스레드와 달리, 작업을 분리해서 수행하므로 실시간으로 사용자에게 응답
- 자원 공유 (Resource Sharing)
- 자신이 속한 프로세스 내의 스레드들과 메모리 / 자원을 공유
- 경제성 (Economy)
- 스레드 생성이 프로세스 생성보다 싸다
- Context Switching의 오버헤드 또한 스레드가 더 경제적
- 확장성 (Scalability)
- 한 프로세스는 한 프로세서에서만 수행 가능한 싱글 스레드와 달리, 한 프로세스를 여러 프로세서에서 수행 가능
- 응답성 (Responsiveness)
- 단점
- 동기화 문제 : 임계 영역 (Critical Section)
- 둘 이상의 스레드가 동시에 실행하면 문제를 일으키는 코드 블록 → 동기화 필요
- 과한 동기화 → 과한 Lock → 병목 현상 → 성능 저하
- 동기화 방법 : 뮤텍스 / 세마포어
- 스레드 생성 시간으로 인한 오버헤드
- Context Switching, 동기화 등 이유로 인함
- 동기화 문제 : 임계 영역 (Critical Section)
2. 자바의 멀티 스레드
2.0. Java의 스레드 모델
- 쓰레드의 종류
- OS 쓰레드 : OS 커널 레벨에서 생성되고 관리되는 쓰레드
- CPU에서 실제 실행되는 단위이자, CPU 스케쥴링의 단위
- 사용자 코드, 커널 코드 모두 실행
- 유저 쓰레드 : 쓰레드 개념을 프로그래밍 레벨에서 추상화한 것
- Java의 Thread 클래스가 여기 해당
- 쓰레드와 관련된 시스템 콜은 이미 추상화된 Thread 클래스를 통해 사용
- 시스템 콜 : 프로그램에서 OS 커널이 제공하는 서비스를 이용하고 싶을 때 사용
- OS 쓰레드와 유저 쓰레드가 연결 되는 방식에 따라 One-to-One, Many-to-One, Many-to-Many 모델이 존재
- Java는 One-to-One 모델 : OS 쓰레드와 유저 쓰레드가 1:1로 연결
- OS 쓰레드 : OS 커널 레벨에서 생성되고 관리되는 쓰레드
- 자바의 멀티 쓰레드 구현 방법
- Runnable 인터페이스를 구현
- Thread 클래스를 상속
2. 1. Runnable 인터페이스를 구현
- 추상 메서드 run() 하나만 있는 함수형 인터페이스
- 객체 인스턴스를 Thread 객체 생성자에 전달한 뒤 start() 메서드 호출
- start() 메서드 호출 시 새로운 스레드가 생성, 생성도니 스레드에서 run() 메서드 실행
- Example
public class HelloRunnable implements Runnable {
@Override
public void run() { // 쓰레드가 수행할 작업을 작성
System.out.println("hello");
}
}
/* 실행 */
public class HelloRunnable implements Runnable {
@Override
public void run() {
System.out.println("hello");
}
public static void main(String[] args) {
HelloRunnable runnable = new HelloRunnable();
Thread thread = new Thread(runnable);
thread.start();
}
}
2.2. Thread 클래스를 상속
- java.lang 패키지 안에 Runnable 인터페이스를 구현한 클래스
- 오버라이딩한 run() 메서드가 있고, 본 스레드를 실행 하는 start() 메서드도 있음
- Example
public class HelloThread extends Thread{
@Override
public void run() { // 쓰레드가 수행할 작업을 작성
System.out.println("hello");
}
}
/* 생성한 스레드 실행 */
public class HelloThread extends Thread{
@Override
public void run() {
System.out.println("hello");
}
public static void main(String[] args) {
HelloThread thread = new HelloThread();
thread.start();
}
}- main 스레드
- 자바 프로그램이 가지는 최소 한 개의 스레드
- JVM이 생성하는 것으로, 자바 프로그램이 실행되면 작업을 수행
- 각 스레드는 별도의 호출 스택을 가진다
- JVM은 스레드들을 스케줄링하여 CPU 자원 할당
3. 스프링의 멀티 스레드
3.0. Spring에서 기본적으로 사용하는 방식
- Spring - 기본적으로 멀티 쓰레드, 동기 방식 사용
- Thread per Request 모델 : 하나의 요청을 처리하기 위해 하나의 쓰레드 사용

- 3개의 요청이 3개의 쓰레드 A, B, C에 할당
- A 쓰레드가 어떤 요청을 처리할 때 I/O 작업이 필요해지면 A 쓰레드는 Blocking
- 다른 요청이 들어오더라도 A 쓰레드는 해당 요청 처리가 끝나지 않았기 때문 (동기의 순차처리)
- Spring boot를 사용할 경우, 기본적으로 쓰레드 풀에 200개의 쓰레드를 만들어 둠
- 요청마다 하나의 쓰레드를 사용하기 때문에, 매번 쓰레드를 생성하면 비용 많이 소모
- 멀티 쓰레드 / 동기 방식으로 많은 양의 트래픽 처리 가능
- But, App 처리량을 늘리기 위해서는 쓰레드 개수 늘려야 함 → 컨텍스트 스위칭 비용 증가 → 메모리 사용량 증가 → 쓰레드 개수 늘리는 방식 한계 有
- 쓰레드 개수 늘리지 않고 처리량 늘리는 방법 → 비동기 방식
- 비동기 방식으로 구현하는 방법 3가지
- Spring Webflux
- 가상 쓰레드
- @Async
3.1. Spring Webflux
- 기존 방식에 처리량에 한계가 있을 때, 비동기 / Non-Blocking 방식의 App 개발을 지원하는 모듈
- Reactive 프로그래밍 방식
- 코드를 작성하고 이해하는 데 어려움
- 기존 자바 프로그래밍은 쓰레드 기반이기 때문에 새롭게 작성해야 함
💡 리액티브 프로그래밍 (Reactive Programming)
- 데이터 흐름과 변화에 반응하는 시스템을 구축
- 리액티브 프로그래밍을 하며 데이터를 비동기적으로 처리
- Reactive 프로그래밍으로의 재작성 문제로 인해,
기본적인 Spring 방식을 사용하되 트래픽이 많은 서비스만 부분적으로 채택해서 사용
3.2. 가상 쓰레드
- 2023년 9월 Java21에 나오면서 도입
- OS 쓰레드와 1:1 연결되지 않고, JVM 자체적으로 스케쥴링하여 Carrier Thread를 통해 연결

- 기존) 요청을 처리하는 쓰레드가 Blocking이 발생 → OS 쓰레드도 Blocking
- 가상 쓰레드) Blocking 발생 시, 내부 스케쥴링을 통해 OS와 연결된 Carrier 쓰레드는 다른 가상 쓰레드의 작업을 처리
- 결과적으로 OS 쓰레드는 Blocking X
- 처리량 한계가 있는 기존 MVC 방식 보완, 작성 / 이해가 어려운 Spring Webflux 단점 보완
3.3. @Async
- @Async 어노테이션 : 비동기 실행 메서드 간편하게 구현 가능
- 스프링이 관리하는 별도의 스레드 풀에서 실행
- 비동기 작업은 TaskExecutor 인터페이스를 통해 실행
- TaskExecutor 인터페이스와 구현체들를 사용하여 스레드 풀 생성 및 사용 가능
- 해당 인터페이스를 구현하여 직접 스레드풀 관리 가능
- 구현체 : SimpleAsyncTaskExecutor , ThreadPoolTaskExecutor
3.3.1. @Async 어노테이션
- @Async 를 통해 실행된 비동기 함수는 별도의 스레드로 실행
- @Async를 사용하기 위해서는 @EnableAsync 선언 필요
- Example
- AsyncService.java
- 비동기로 asyncMethod 선언
@Slf4j
@Service
public class AsyncService {
@Async
public void asyncMethod() {
try {
Thread.sleep(2000);
log.info("thread name: {}", Thread.currentThread().getName());
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}- AsyncConfig.java
- @Async를 사용하기 위해서는 @EnableAsync 선언 필요
@EnableAsync
@Configuration
public class AsyncConfig {
}- Controller.java : 비동기 동작을 확인하기 위한 컨드롤러
@Slf4j
@RestController
@RequestMapping(value = "/")
public class ExampleController {
private final AsyncService asyncService;
public ExampleController(AsyncService asyncService) {
this.asyncService = asyncService;
}
@GetMapping
public ResponseEntity<Void> temp() {
log.info("controller start ...");
asyncService.asyncMethod();
log.info("controller end ...");
return new ResponseEntity<>(HttpStatus.OK);
}
}
3. 3.2. TaskExecutor : @Async의 스레드풀 관리
- @Async 가 비동기로 동작할 때, TaskExecutor 인터페이스를 통해 실행
- 여기서 사용되는 구현체에는 SimpleAsyncTaskExecutor , ThreadPoolTaskExecutor 가 있다
- SimpleAsyncTaskExecutor
- 스프링 환경에서 기본으로 사용
- 매 실행마다 새로운 스레드를 생성하여 작업 실행
- 스레드 재사용 X → 성능 이슈 주의
- 사용 지양하기를 권장
- Example) AsyncConfig.java
@EnableAsync
@Configuration
public class AsyncConfig {
@Bean
public Executor getAsyncExecutor() {
return new SimpleAsyncTaskExecutor();
}
}- ThreadPoolTaskExecutor
- 스레드풀을 이용해 스레드를 관리
- 스레드 재사용 → 성능 최적화 가능
- Example) AsyncConfig.java
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(100);
executor.setQueueCapacity(50);
executor.setThreadNamePrefix("custom-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.initialize();
return executor;
}
}- ThreadPoolTaskExecutor 의 스레드 풀 설정
- Thread Size
- corePoolSize : 스레드풀에서 기본적으로 유지되는 스레드 수 (default : 1)
- maxPoolSize : 스레드풀에서 사용 가능한 최대 스레드 수 (default : Integer.MAX_VALUE)
- queueCapacity : 스레드풀 작업 큐의 사이즈
- Thread Name
- threadNamePrefix : 생성 스레드 이름에 사용될 접두사
- RejectedExcutionHandler
- TaskRejectedException : 모든 스레드가 작업중이고 BlockingQueue에서도 추가 작업을 받을 수 없을 때 발생하는 예외
- 전략에 따라 예외 발생 대신 다른 선택 가능 : 호출한 곳에서 작업 실행, 해당 작업 스킵, 큐에 오래된 작업 삭제하고 새 작업 추가
- TaskRejectedException : 모든 스레드가 작업중이고 BlockingQueue에서도 추가 작업을 받을 수 없을 때 발생하는 예외
- Thread Size
📌 References
https://320hwany.tistory.com/107
https://akku-dev.tistory.com/89
https://80000coding.oopy.io/80fdeed4-c57b-440b-9f5b-edd62d2dd493
https://f-lab.kr/insight/java-multithreading-basic-spring-utilization
https://devoong2.tistory.com/entry/Spring-Async-사용-방법-및-TaskExecutor-ThreadPool
728x90
'Spring' 카테고리의 다른 글
| [Spring] 스프링의 기본적인 예외처리 / 예외처리 방법 (2) | 2025.06.05 |
|---|---|
| [Spring] 스프링의 디렉토리 구조 : 계층형 / 도메인형 (0) | 2025.06.04 |
| [Spring] 빌드 관리 도구 Maven vs Gradle (0) | 2025.06.04 |
| [Spring] JSP와 Spring에서의 Forward와 Redirect : InternalResourceView / RedirectView (0) | 2024.02.02 |
| [Spring] URL 매핑 : URL 패턴 Servlet URL Mapping / DispatcherServlet (0) | 2024.02.02 |