알고리즘
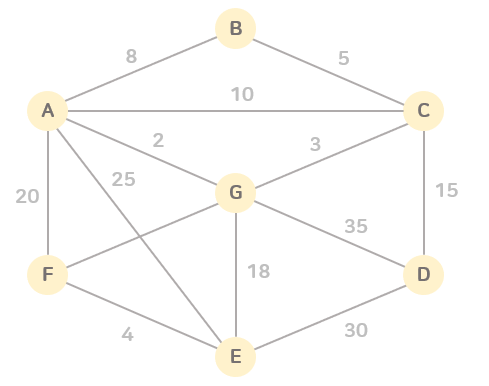
[Algorithm] 자료구조 - 그래프 (Graph)
그래프 (Graph) 네트워크를 표현하는 자료 구조로, 정점(vertex)라 부르는 노드와 정점 사이를 연결하는 간선(edge)의 집합으로 구성되는 자료 구조 - 간선(edge)는 두 노드 간 연결이고, 방향성이 있을 수도 없을 수도 있으며, 비용이 발생할 수 있다 * 깊이 우선 탐색 (DFS, Depth-First Search), 너비 우선 탐색(BFS, Breadth-First Search) 알고리즘으로 그래프 탐색 가능 * 깊이 우선 탐색 (DFS, Depth-First Search), 너비 우선 탐색(BFS, Breadth-First Search) 알고리즘으로 그래프 탐색 가능 💡 자료 구조 : codesyun.tistory.com/106 [Algorithm] 자료 구조(Data Structure..

[Algorithm] 자료구조 - 해시 테이블 (Hash table)
해시 테이블 (Hash table) 키(key)에 값(value)을 매핑하는 자료 구조 - 해시 테이블의 각 위치는 슬롯(slot)이라고 한다 - 해시 함수(hash function)로 배열의 인덱스를 계산한다 - 실제 저장된 키의 개수가 가능한 키의 개수보다 적을 때 해시 테이블을 사용 - 해시 테이블은 배열의 개념을 일반화한다 - 딕셔너리를 구현하는 데 유용한 자료 구조 해시 함수로 데이터를 저장하는 과정 1. 데이터를 저장할 크기 M인 배열을 생성, 이 배열을 해시 테이블이라 한다 2. 해시 함수로 키의 해시 코드를 찾는다 3. 해시 코드를 해시 테이블의 크기로 나눈 나머지를 구해 데이터를 저장할 인덱스로 사용 4. 데이터를 지정된 인덱스에 저장 해시 테이블에서 해시 함수로 데이터를 찾는 과정 1...

[Algorithm] 자료구조 - 트리 (Tree), 이진 트리(Binary tree)
트리 (Tree) 계층형 자료 구조 트리의 최상위 원소를 루트(root)라고 하고, 나머지 모든 원소는 부모 원소가 있고 0개 이상의 자식 원소를 가진다 자식 노드가 없는 노드는 리프 노드(leaf node)라고 한다 이진 트리 (Binary tree) 가장 기본적인 트리의 유형 각 노드에 왼쪽, 오른쪽 자식이라는 최대 2개의 자식이 있는 트리 이진 탐색 트리 (BST, Binary Search Tree)는 다음 방법으로 노드를 정렬한다 1. 왼쪽 하위 트리의 키(key)가 부모 노드의 키보다 작거나 같다 2. 왼쪽 하위 트리의 키가 부모 노드의 키보다 크다 이진 탐색 트리의 API와 시간 복잡도 API (Application Programming Interface) - Insert(k) : 트리에 새 ..

[Algorithm] 자료구조 - 힙(Heap)과 우선순위 큐(Priority Queue)
우선순위 큐(Priority Queue) 일반적인 큐는 조건 없는 FIFO(First-In-First-Out) 구조이지만, 우선순위 큐(Priority Queue)는 우선순위에 따라 특별한 순서로 원소를 추출하는 것이다 이진 힙 자료구조로 구현한다 힙 (Heap) 레코드는 배열에 저장하며, 모든 노드는 부모의 값이 자식 값보다 크다(또는 작다)는 동일한 규칙을 따르는 자료 구조 완전 이진 트리(complete binary tree)를 기본으로 한다 💡 이진 트리 : codesyun.tistory.com/112 [Algorithm] 트리 (Tree), 이진 트리(Binary tree) 트리 (Tree) 계층형 자료 구조 트리의 최상위 원소를 루트(root)라고 하고, 나머지 모든 원소는 부모 원소가 있고 ..

[Algorithm] 자료구조 - 큐 (Queue)
큐 (Queue) 선입 선출 (FIFO, First-In-First-Out) 형태의 자료 구조 먼저 추가한 원소가 먼저 제거된다 큐의 사용 1. 공유 자원 접근 (예 : 프린터) 2. 멀티 프로그래밍 3. 메시지 큐 4. 그래프와 트리의 너비 우선 탐색(BFS, Breadth First Search) 큐의 API와 시간 복잡도 - Add(k) : 큐의 맨 뒤쪽에 새 원소 k를 추가 - Remove() : 큐의 맨 앞 원소 값을 반환한 후, 삭제 - Front() : 큐의 맨 앞 원소의 값을 반환 - Size() : 큐의 원소 개수를 반환 - IsEmpty() : 큐가 비었으면 1을 반환 > 큐의 모든 연산은 시간 복잡도가 O(1) 💡 자료 구조 : codesyun.tistory.com/106 [Algor..

[Algorithm] 자료구조 - 스택 (Stack)
스택 (Stack) 한 쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 자료 구조 후입 선출(LIFO, Last-In-First-Out) 전략을 따르므로, 마지막에 추가한 원소가 먼저 제거된다 스택의 사용 1. 재귀(recursion) 호출 2. 후위 표현식(postfix expression)의 계산 3. 스택으로 구현하는 백트래킹(backtracking) 4. 트리와 그래프의 깊이 우선 탐색(DFS, Depth-First Search) 5. 10진수를 2진수로 변환하기 스택의 API와 시간 복잡도 - Push(k) : 스택의 맨 위에 값 k를 추가 - Pop() : 스택의 맨 위 원소 값을 반환한 뒤 제거 - Top() : 스택 맨위 원소의 값을 반환 - Size() : 스택의 원소 개수를 반환 - IsE..

[Algorithm] 자료구조 - 연결 리스트 (Linked list)
연결 리스트 (Linked List) 각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 구조이다 데이터를 저장할 때 그 다음 순서의 데이터가 있는 위치를 데이터에 포함시키는 방식으로 자료를 저장 연결 리스트의 특징 - 동적 자료 구조 - 원소에 직접 접근할 수 없어서 배열보다 성능이 느리다 - 저장할 원소의 개수를 알지 못할 때 유용 - 종류 : 선형(linear), 원형(circular), 이중(doubly), 이중 원형(doubly circular) 등 💡 배열 : codesyun.tistory.com/107 [Algorithm] 배열(Array) 배열 같은 자료형의 다중 원소 집합 순서대로 번호(인덱스, index)가 붙은 원소들이 연속적인 형태로 구성되어 있다 배열의 사용과 시간복잡도 1..

[Algorithm] 자료구조 - 배열(Array)
배열 같은 자료형의 다중 원소 집합 순서대로 번호(인덱스, index)가 붙은 원소들이 연속적인 형태로 구성되어 있다 배열의 API과 시간복잡도 API (Application Programming Interface) - k번째 위치에 원소 삽입 : 상수 시간 O(1)에 k번째 위치에 값 저장 - k번째 위치에서 값 읽기 : 상수 시간 O(1)에 k번째 위치에 저장된 값에 접근 - k번째 위치에 저장된 값 대체하기 : 상수 시간 O(1)에 k번째 위치에 저장된 값을 새 값으로 대체 배열의 단점 - 고정된 크기를 가지기 때문에 저장할 수 있는 값이 한정되어 있다 - 더 많은 값을 고정하기 위한 방법 - 크기가 충분한 새 배열을 재할당 / 복사 -> 연산이 느리다 - 처음부터 더 큰 배열을 할당 -> 메모리 ..

[Algorithm] 자료구조(Data Structure) 란?
자료구조(Data Structure) - 데이터의 구체적 표현이며, 데이터를 프로그래머 관점에서 정의한다 - 데이터를 메모리에 저장하는 방법을 나타낸다 - 문제 유형에 따라 최적의 자료 구조를 선택해야 한다 자료 구조의 종류 💡 자주 사용되는 자료구조들 다음 자료 구조의 링크를 클릭하면 해당 게시글로 넘어갑니다! 🏃🏃🏃 - 배열 : codesyun.tistory.com/107 [Algorithm] 배열(Array) 배열 같은 자료형의 다중 원소 집합 순서대로 번호(인덱스, index)가 붙은 원소들이 연속적인 형태로 구성되어 있다 배열의 사용과 시간복잡도 1. k번째 위치에 원소 삽입 : 상수 시간 O(1)에 k번째 codesyun.tistory.com - 연결 리스트 : codesyun.tistory...

[Algorithm] 빅오 표기법과 시간 복잡도의 개념 및 예제
알고리즘에서 중요한 속성 1. 정확성 : 주어진 입력을 모두 처리하며 올바르게 출력해야 한다. 2. 효율성 : 문제를 효율적으로 해결해야 한다. 두 가지 변수로 측정 - 시간 복잡도 : 알고리즘이 얼마나 빠르게 결과를 출력하는지 측정, 입력 크기 n에 대한 시간 함수 T(n)으로 표현 - 공간 복잡도 : 원하는 결과를 얻기 위해 알고리즘이 얼마나 메모리를 사용하는지 측정, 입력 크기 n에 대한 메모리 사용 함수 S(n)으로 표현 빅오 표기법 (big-O) - 점근적 분석의 한 방법 - 수학적 정의 - cg(n)은 모든 n >= n0에 대해 f(n)의 상한이다. - 최고차항의 차수로 표현하고 계수와 낮은 차수의 항은 무시한다. (예시) n^2 + n = O(n^2) 시간 복잡도 알고리즘에 주로 나오는 시간..